Que es Big Data?
Damián Barsotti
Facultad de Matemática Astronomía Física y Computación
Universidad Nacional de Córdoba

This work is licensed under a
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

Presenter Notes
Jampp
- Empresa argentina mayorista de publicidad en apps de celulares
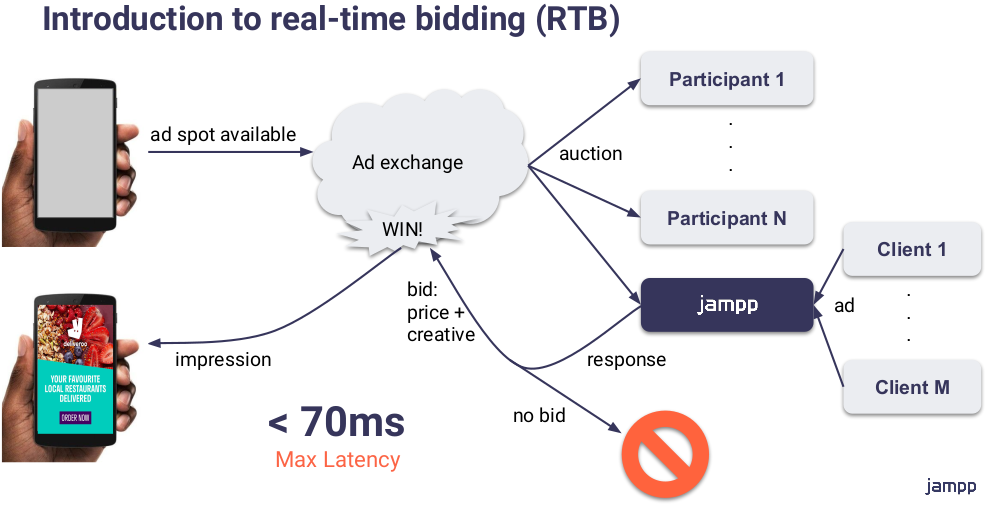
- +100TB procesados por día
- +600TB de datos almacenados y consultados
- +70 instancias EMR
Presenter Notes
- Otro ejemplo local
- Doctorado de FaMAF maneja la infrestructura
- Con instancias spot de Amazon
- Bajísima latencia en Amazon!
- Ver EMR
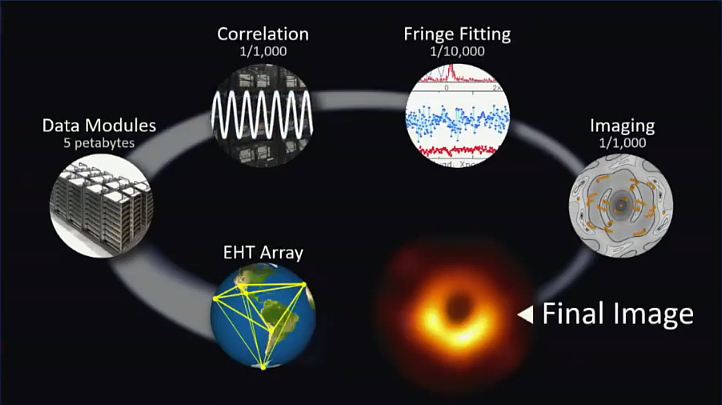
Foto del agujero negro
5 Petabytes = 5000 Terabytes de información
= mp3 de 5000 años de duración.

- los 5 PB transportados por avión
Presenter Notes
- Telescopio de escala planetaria formado por 8 radiotelescopios
- Interesante problema de datos muy distribuidos
- Problemas de velocidad de red que se veran mas adelante
- Media tonelada de hd
- shipping those drives from Hawaii to MIT works out to 14 gigabytes per second (112 gigabits per second)
- hd rellenos de helio para que no fallen en lugares inospitos
- Event Horizon Telescope (EHT)
- Reconstruccion de Imagen con Regularized Maximum Likelihood y Clean (deconvolucion)
- 2 equipos RML y dos Clean
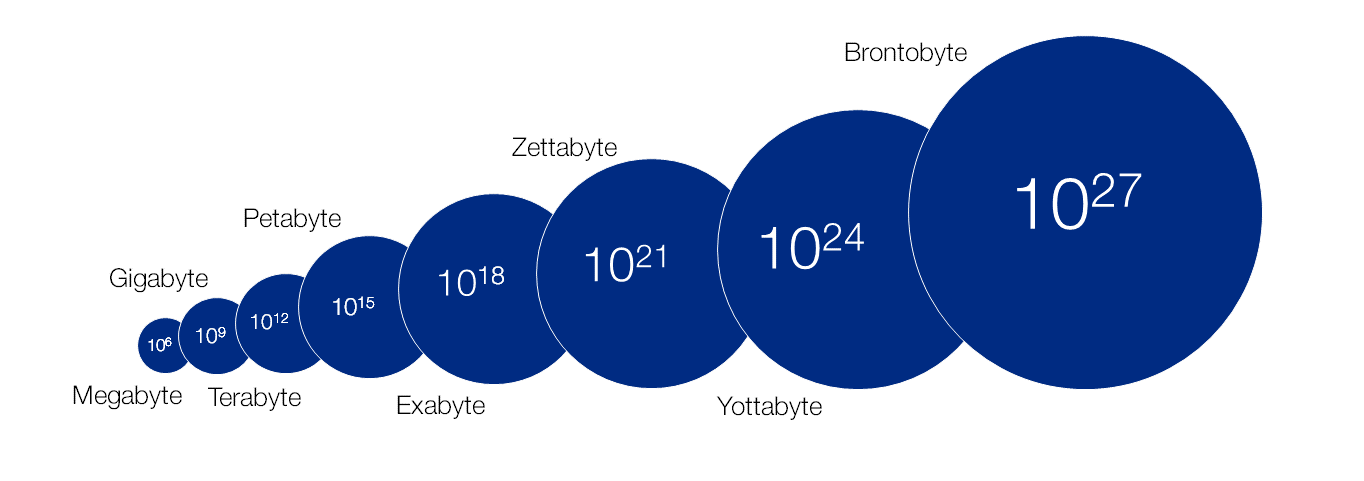
Aún más palabras
- 1 Brontobyte = 1000 Yottabytes
y aun más
- 1 Geopbyte = 1000 Brontobytes
Presenter Notes
Perspectiva
- Universo digital será de 40 Zettabytes a fines del 2020
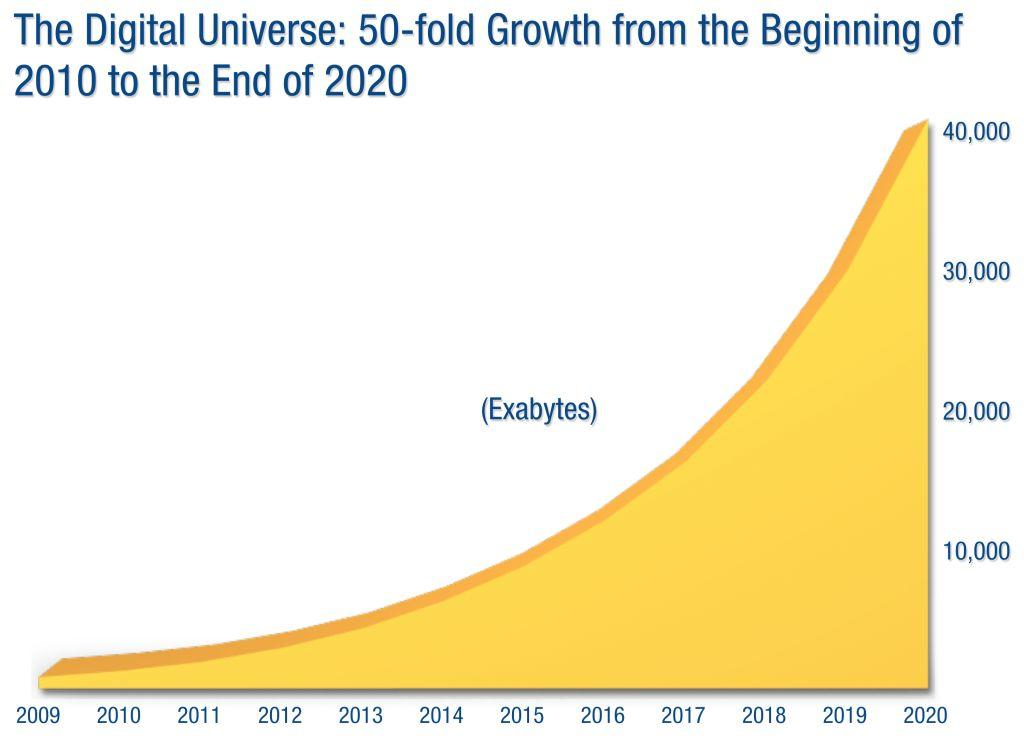
The digital Universe in 2020 http://www.emc.com/collateral/ analyst-reports/idc-the-digital-universe-in-2020.pdf
Presenter Notes
- Estudio del 2012
- Actualmente la predicciones se han superado
Aún más
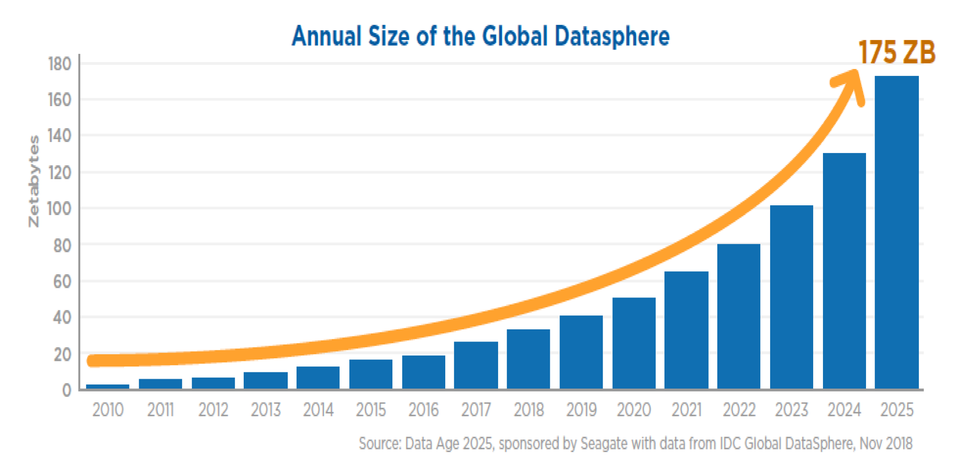
https://www.seagate.com/files/www-content/ our-story/trends/files/idc-seagate-dataage-whitepaper.pdf
Presenter Notes
- Estudio del 2018
- Mas para el 2020
- 2018 33 ZB
Cluster de computadoras
- Muchas computadoras (nodos) en red
- Hardware escalable

Presenter Notes
- No queda otra que usar muchas mauinas: no se pueden o no escala procesar todo en una máquina
- Hardware escalable: se pueden agregar nodos y no mover todo a una nueva máquina
Almacenamiento de Datos
Servidor de disco en red
- Filers
- Scale-Out NAS(1) = 50 PB
- Se transporta datos a programas (clásico).
- Modelo de programación Network Programming (MPI).
- Problema: red es lenta.

(1) NAS: Network-attached storage.
Presenter Notes
- Scale-Out NAS es la solucion mas conocida
- Hace 10 años que infiniband está en 50GB/s (con muy baja latencia).
- Veremos este fenómeno unas filminas mas adelante
- Otros problemas: MPI dificil de programar (tiempo de desarrollo), tolerancia a fallas o resilencia
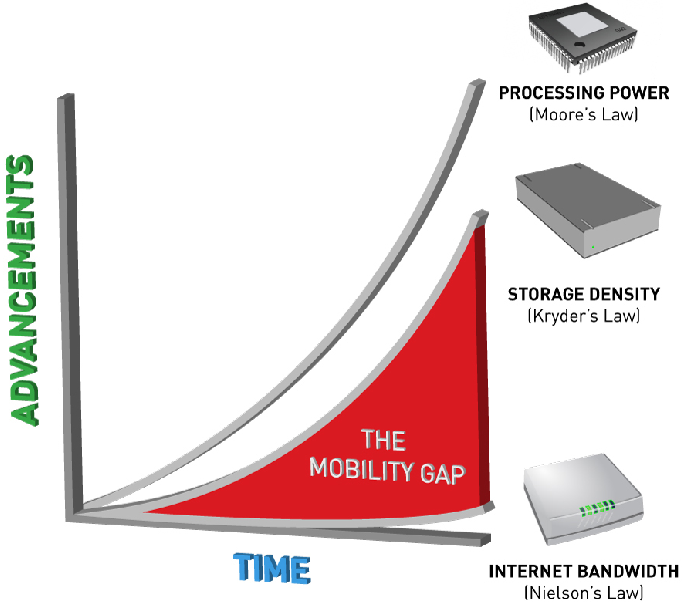
No es posible
- Ley de Kryder: densidad almacenamiento crece 59% por año.
- Ley de Nielsen: velocidad red crece 50% por año.
Presenter Notes
Leyes parecidas a ley de moore
Ley de Moore: procesamiento crece 60% cada año
(pero con techo)
(o doble cada 18 mese)
Esto es exponencial
Sacado de Storage & the Mobility Gap (or, why I hate filers)
http://dev.pistoncloud.com/2013/04/storage-and-the-mobility-gap/
Alternativa a Filers
Discos locales en cada nodo

- Distribución de datos en distintas computadoras (nodos)
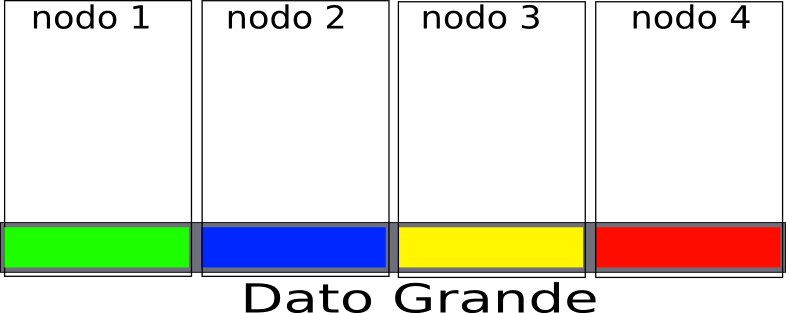
- lectura en paralelo
Presenter Notes
- Los pedacitos de datos se llaman chunks
- HD 2 veces mas lento que red https://gist.github.com/jboner/2841832
- aunque + paralelismo
- SSD 10 veces mas rapido que red https://serverfault.com/questions/238417/are-networks-now-faster-than-disks
Mejora
Replicación de Datos
- Varias copias del pedacito de dato (chunk)

- Datos más cerca de los programas
- Menos red! (mayor localidad de datos)
- Tolerancia a fallos
- Ej: Hadoop File System (HDFS), Google File System (GFS)
Presenter Notes
- FS distribuido
MapReduce
- Ejemplo canónico de Data Flow Programming
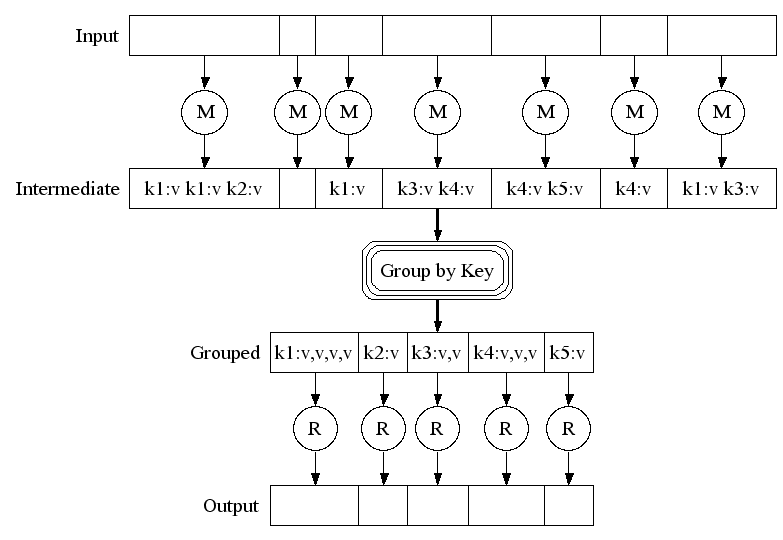
Presenter Notes
Word Count con MR
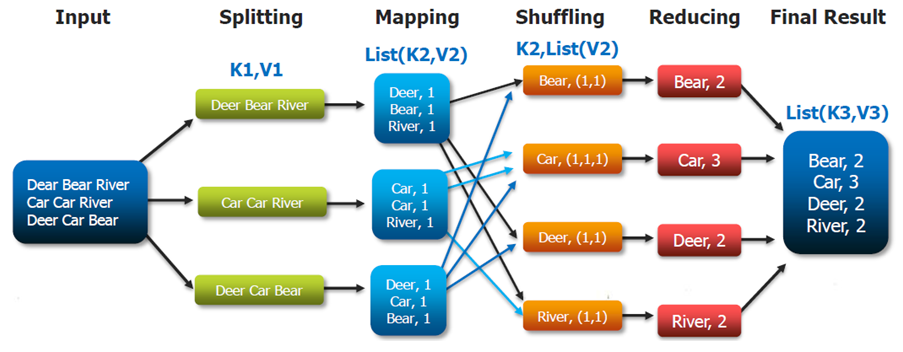
Presenter Notes
Ejemplo: Page Rank
- Multiplica matriz rala por vector muchas veces
- Recrea hash de neighbors y ranks
Presenter Notes
Problema
+iteraciones = + I/O
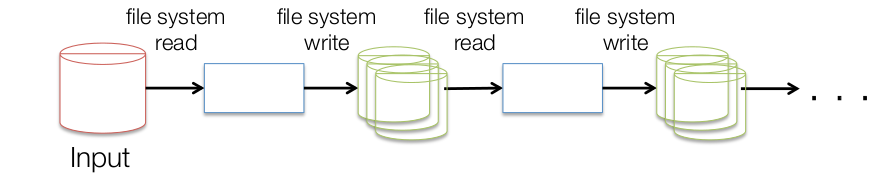
- 90% del tiempo haciendo I/O
- Solución: Spark = MR++ en memoria
Presenter Notes
Implementación Spark
Patrones como grafo de operaciones de alto nivel
- relación temporal entre operaciones (map, reduce, filter, join, etc.)
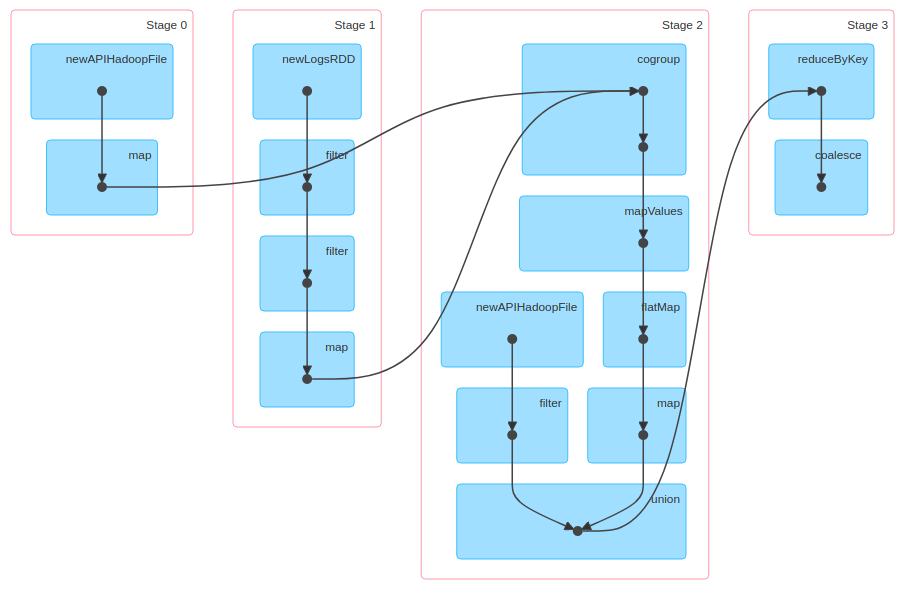
Presenter Notes
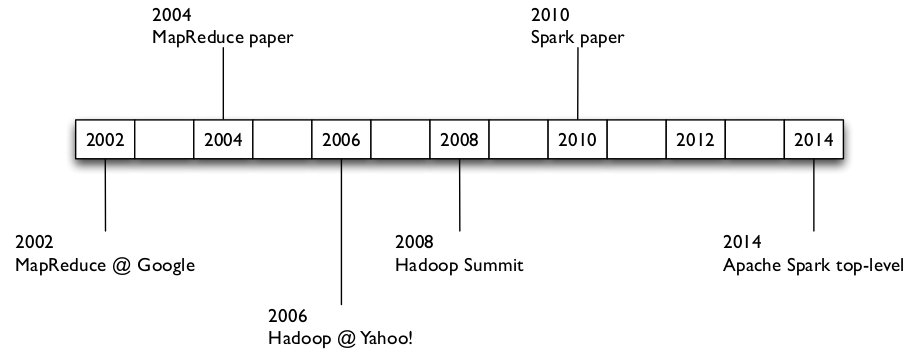
Historia